CX
Privacy-compatible automated contact tracing
If you are following the news, you may have heard about Contact Tracing and how it can help us contain communicable diseases such as COVID-19. Essentially, contact tracing is the process of manually identifying and closely monitoring those in close contact with people that have been diagnosed with an infectious disease. It is commonly performed for diseases such as tuberculosis and measles and it can help by:
- Breaking transmission chains
- Notifying contacts of a potential infection
- Enabling early testing and treatment of vulnerable contacts
However, the large volumes of COVID-19 cases and the speed at which the disease spreads make it difficult to perform accurate and timely contact tracing manually. Imagine trying to remember everyone you came into close contact with yesterday, and the day before, and the day before that. What if it was somewhere public, and you don’t know their name or contact information? Besides being laborious and expensive, the whole process is too slow and therefore less effective at breaking transmission chains.
This is why you may have also heard about Automated Contact Tracing. This is the process of deriving a list of potential contacts using a mobile application, and it could potentially help by enabling a faster and more accurate system when compared to manual contact tracing. To illustrate this, we’ve put together a small simulation.
Simulating disease spread
Inspired by this great article, we have developed a small simulation that illustrates the importance of fast contact tracing for containing infectious diseases. Here we simulate a number of people moving around in an environment. Healthy people are represented by green dots, while infected people are represented by orange dots. When a healthy individual comes in close proximity with an infected individual, there is a high probability (in this case, 80%) that the infection is transmitted. The individuals that are infected continue navigating in the environment until they are isolated, which is when they disappear from the environment.
You will see that a large proportion of the population was infected pretty quickly in the initial stage of the simulation. This is especially problematic because healthcare systems are not prepared to deal with sharp increases in demand in a short period of time.
The effect of tracing speed
This simulation assumed that there was a significant amount of time between the moment an individual is in contact with another infected individual and the moment when that individual is told to self-isolate. The intent is to simulate the long process of manual contact tracing. However, we can shrink that time window considerably with Automated Contact Tracing. In the simulation below we start with a much shorter delay between contact and isolation:
You now see that the increase in the number of cases through time is not as sharp and flattens out at a much lower level than in the previous simulation. You can play around with the delay slider and see what happens if you restart the simulation.
The effect of adoption scale
Another dimension we need to think about is the proportion of people that we can effectively trace and isolate. In manual contact tracing, this is limited by the amount of resource (financial and human) available, as insufficient resource will cause some cases not to be traced and isolated in a timely manner. In automated contact tracing, the proportion of cases we can trace depends directly on how many people adopt automated contact tracing. To illustrate this, here’s a simulation where you can vary the proportion of traceable individuals. In the automated contact tracing scenario, this can be interpreted as the proportion of individuals with a contact tracing application installed.
You’ll be able to see that even though some individuals are traced pretty quickly, others remain navigating in the environment and propagate the infection to to a majority of individuals. This reinforces the necessity for an automated contact tracing solution that can be adpopted by as many individuals as possible.
Automated contact tracing
There are currently several independent efforts to develop automated contact tracing applications, but they differ substantially in their design. The most notable differentiation has to do with how the system identifies contacts associated with a given case. One approach is to do this identification on a server that is controlled by a third-party, such as the government, public health authorities or a private company. This is known as a centralized approach because all the information required is held in a server controlled by some entity.
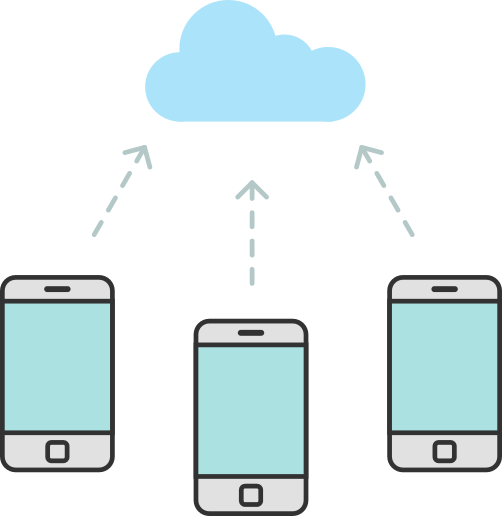
While this theoretically works, the method has severe implications from a privacy perspective. In particular, anyone with access to the server would be able to view all the interactions for any individual device, potentially pinpointing the locations at which they had occurred and potentially identifying the device owners. This is likely to discourage users from adopting the application, which in turn will limit its effectiveness.
Fortunately, there is a better way. In particular, there is no reason why we cannot keep all the information that is required for identifying hazardous contacts in each mobile device. This approach is known as decentralized. In this case, third-parties such as public health authorities do not have access to all the data collected by the application: they only participate by confirming and publishing information about hazardous contacts.
There are other design aspects that differ between the various applications that are currently under development, such as how often they transfer data and what kind of data is transferred, which in turn can have consequences on factors like adoption rate and tracing speed. As we’ve illustrated above — and others have addressed scientifically here — these factors can have a great impact on the overall effectiveness of automated contact tracing.
Below we present CX, an architecture for automated contact tracing that prioritises privacy and efficiency. If you are an expert and would like to jump straight into the technicalities, please read the specification.
CX: Privacy-compatible distributed contact tracing
CX is an architecture for privacy-compatible distributed contact tracing, designed for use in pandemics such as Covid-19. Similar to other tools, it operates using a model of proximity-based contact detection over one or more local area broadcast media such as Bluetooth Low Energy (BLE). However, unlike some other tools, it does so in a privacy-preserving way.
Among other features, the architecture provides:
- Zero information leakage: for users who do not choose to disclose any information for contact tracing (e.g. because they are never diagnosed with the disease), the information broadcast by that user is indistinguishable from an ideal random bitstring.
- Zero collection of location information: the devices running the protocol can choose to do so with no source of location information, and can therefore guarantee that no location history is collected.
- Zero privilege: there is no third party, central authority, or software provider who has privileged access to any data.
- Trusted diagnoses: governments and public health services provide trusted and digitally signed medical diagnoses, with the ability for users to distinguish between self-reported symptoms and medical test results.
- Revocable diagnoses: a negative medical test result can supersede initial self-reported symptoms, allowing alerted users to minimise unnecessary time spent in isolation.
- Distributed contact identification: users can identify only their own hazardous contacts, and no central authority has access to the information required to identify contacts.
CX lowers the barrier to adoption
CX lowers the barrier to adoption by addressing key concerns around privacy and device efficiency.
First and foremost, CX never provides any sensitive information to a third-party. Namely, the information that is exchanged between devices when they are in proximity is stored on the mobile devices themselves, and is never shared with anyone else. This eliminates the possibility of third-parties tracking individuals or using their data for unauthorized purposes. The fact that sensitive data never leaves the device should reassure even the most skeptical users and therefore increase the likelihood of adoption.
Second, CX is easy on your device and on your data. Any automated tracing application will require transferring some data between devices and a server. If you consider that millions of users will be using the application and that data is being collected on a very frequent basis (say, every 5 minutes), you’ll quickly realize that this may require significant power from your device, as well as a considerable volume of data allowance. CX demands little from your device — in fact, it can even run on cheap microcontrollers (which could be important in places where mobile phones are not available). Additionally, CX makes use of a smart method to reduce the data transferred by approximately 99.9%. It will also work if you are temporarily beyond your allowance limits. This is critical to ensure that people that cannot afford expensive data plans can still use the application.
CX enables near instantaneous contact tracing
Recent research suggests that it is very important to notify people quickly, and that even a 24 hour delay for a confirmed diagnosis has a huge negative effect. This means that you must alert people for unconfirmed diagnoses, which in turn means that you must have a mechanism for cancelling the alerts, otherwise you end up with most people in a state of lockdown alert, which isn’t really much better than a blanket lockdown. CX supports revoking a previous alert if it is found to be a false one, thereby minimising the time users need to spend in isolation.
How does CX work?
Similar to other tools, CX operates using a model of proximity-based contact detection over one or more local area broadcast media such as Bluetooth Low Energy (BLE). However, unlike other tools, it does so in a privacy-preserving way. But how?
The idea is to exchange apparently random codes between devices when these are in proximity. On their own, these codes do not convey any sensitive information about you or your device.

But if these codes are random, how can they be helpful for contact tracing? The answer is that they are not completely random. CX keeps a secret value on your device and uses this value to generate random codes. This secret value is called a seed. The interesting thing is that the sequence of random codes generated with a particular seed is unique to a particular seed value, but the generated random values alone tell you nothing about which seed has been used to generate them. Let’s see this in action.
The input box is the value of your seed — go ahead and enter any number you’d like there. This value is then used to generate the random codes on the right. As you can see, the generated codes look random. If you now modify the seed value, even if you only change one of the digits, you’ll see that the generated codes are completely different. However, if you change the value back to the initial one, you’ll get back the same codes.
This means that the random codes cannot be used to identify the original seed, but a given seed is associated with one and only one sequence of codes.
When two devices come into proximity, they exchange these random codes and store them locally. Over time, your device will accumulate a list of random codes that were pushed by other devices in its vicinity, as well as a list of codes it has pushed to other devices:
Now, say that a friend of yours then happens to be infected. If they wish to, their healthcare provider can generate an authorization code that will allow your friend to upload their seed value to a server. This is important because it greatly reduces the amount of data that has to be transferred to and from participating devices.
The server can then publish these seed values and the mobile application can check if any of the published seeds matches the random codes stored locally. If it does, it can immediately notify the user and the user can self-isolate.
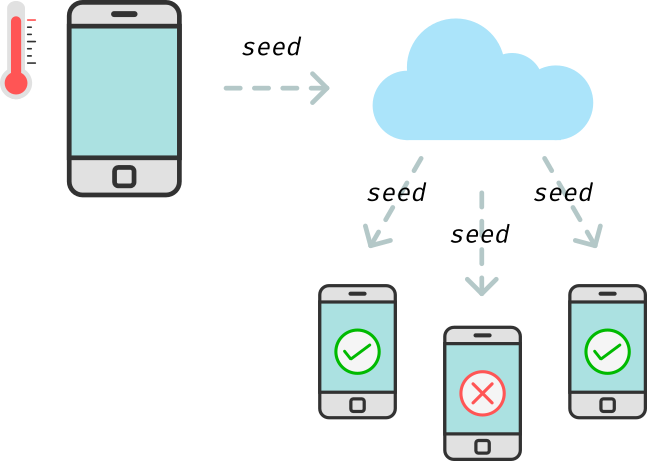
Importantly, the healthcare provider never has access to sensitive information, such as who you’ve met and where you were: it only receives the seed value we’ve mentioned above. Additionally, individual users alone do not hold any sensitive information about other users. In this way, none of the parts has access to enough information that can violate your privacy. Rather, the tracing is done in collective manner.
Conclusion
CX is an architecture which minimises the compromises that users will have to make in order to participate in an automated contact tracing system. This means that CX has all the characteristics that are necessary to maximise adoption rate. Simultaneously, CX provides all the functionality required to perform instantaneous contact tracing in a resource efficient manner. CX is open, which means that anyone can inspect it and see how it works. You can find all of CX’s advantages and other information here.
Thanks to...
- Michael Brown, the architect behind CX.
- Matthew Conlen, the author if Idyll (the tool used to write this article)
- Ksenia Shchegolkova and Chris Seal for comments and suggestions